AI Benchmarks
AI benchmarks are standardized evaluation frameworks that measure how well AI models perform on specific tasks—from mathematical reasoning and code generation to language understanding and real-world problem-solving. They serve as the yardstick by which the AI industry measures progress, compares models, and identifies capability gaps.
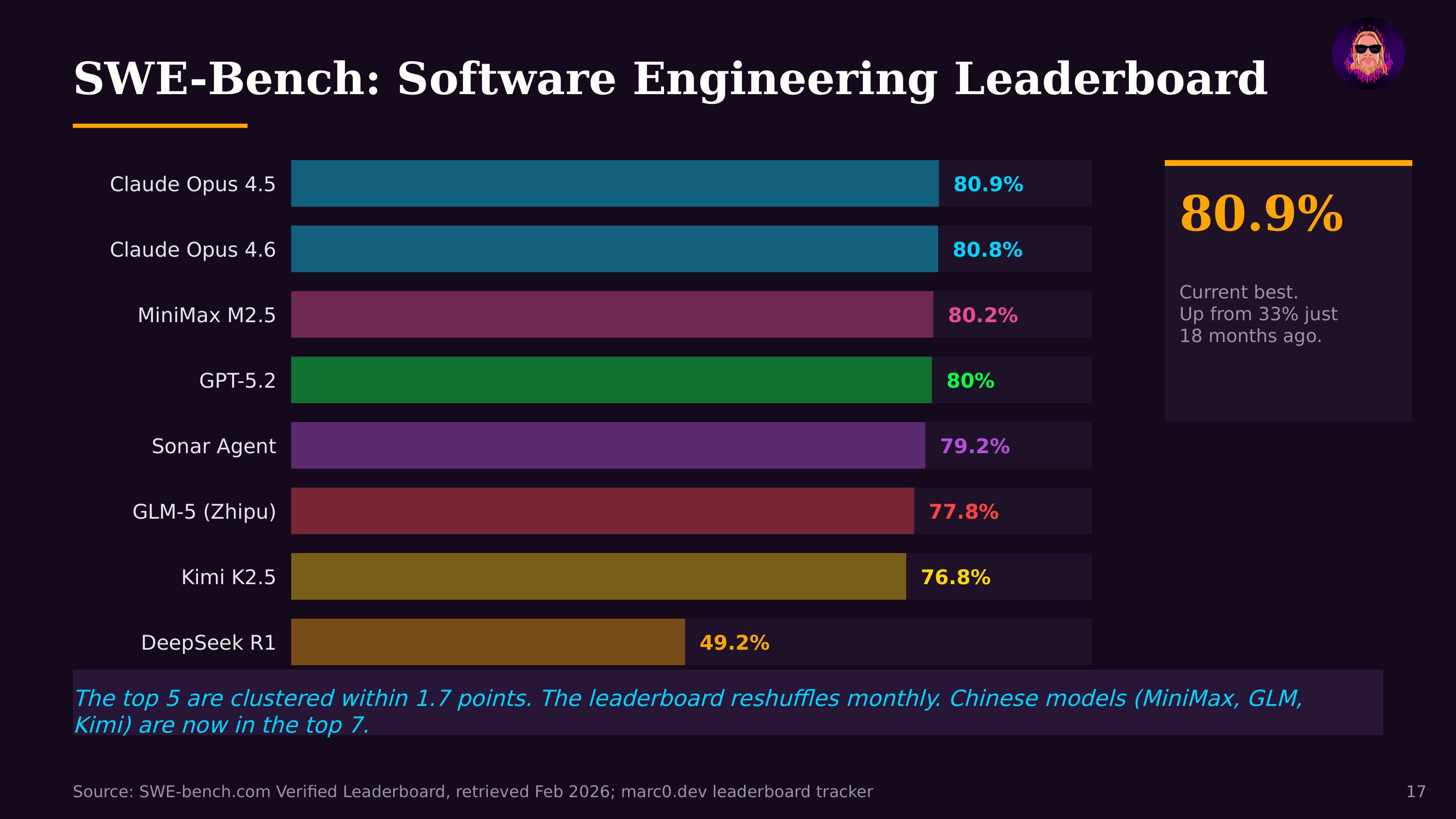
The benchmark landscape has evolved to match model capabilities. Early benchmarks (GLUE, SuperGLUE) tested basic language understanding and were quickly "saturated"—frontier models scored near-perfect. Current benchmarks target harder problems: MMLU tests broad knowledge across 57 subjects, HumanEval and SWE-bench measure coding ability, MATH and GSM8K test mathematical reasoning, ARC-AGI evaluates novel problem-solving. METR's autonomous task horizon benchmark—measuring how long an agent can work independently—has become one of the most practically significant, showing a doubling from minutes to 14.5 hours in 18 months.
Benchmarks shape the AI race in ways both productive and distortive. They provide legible metrics for comparing models (Anthropic, OpenAI, Google, and others publish benchmark scores with each release) and focus research attention on measurable capabilities. But they also create optimization incentives that may not align with real-world usefulness—models can be specifically tuned to excel on benchmark tasks without proportional improvement on practical applications. The gap between benchmark performance and real business impact (6% of organizations seeing >5% EBIT impact despite impressive benchmark scores) suggests this disconnect is significant.
The most impactful recent development is the emergence of agentic benchmarks—tests that evaluate not just single-turn responses but multi-step autonomous behavior. SWE-bench (can the model fix real GitHub issues?), WebArena (can it navigate websites to complete tasks?), and METR's task horizon measurement capture the capabilities that matter for AI agents operating in the real world. These benchmarks are becoming the new standard by which the industry measures meaningful progress.