AI Inference
AI inference is the process of running a trained AI model to generate predictions, responses, or outputs based on new input data. If training is teaching the model, inference is using it. Every time you interact with ChatGPT, Claude, or any LLM-powered application, you're triggering inference.
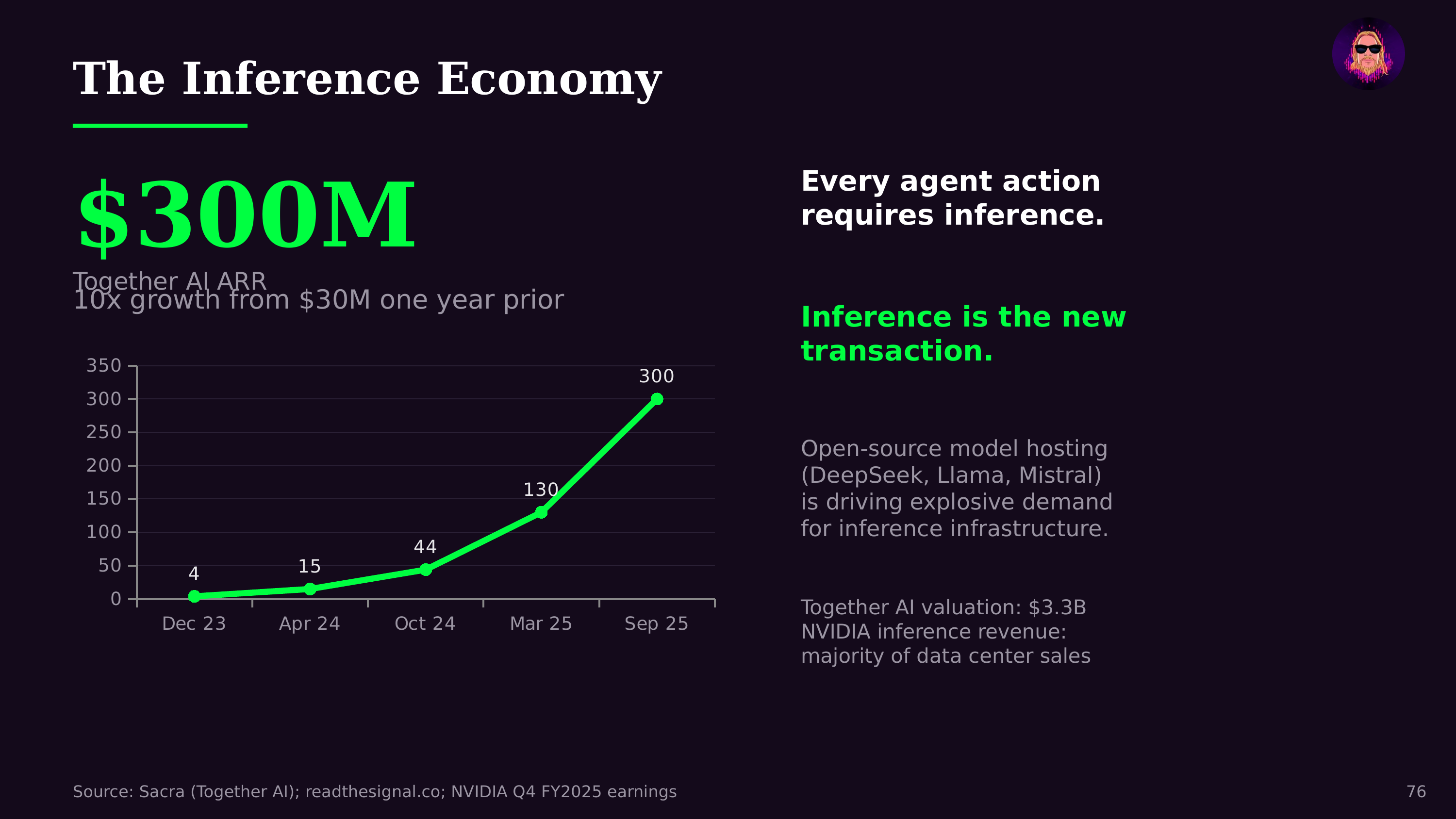
The economics of inference are the most consequential cost curve in modern technology. Per-million-token pricing has fallen from $30 in early 2023 to $0.10–$2.50 by early 2026—a 92% decline in roughly three years. Open-source models like DeepSeek have been the primary catalyst, demonstrating frontier-quality inference at $1.50 per million tokens and forcing aggressive price competition across the industry.
This cost deflation is enabling entirely new categories of applications. When inference was expensive, AI was reserved for high-value tasks. As costs approach commodity pricing, it becomes viable to run AI on every email, every customer interaction, every line of code, every piece of content. AI agents that operate autonomously for hours—browsing the web, writing code, managing projects—become economically feasible only because inference costs have crossed a critical threshold.
The infrastructure demands of inference are massive and growing. Unlike training, which is a one-time (though expensive) process, inference runs continuously as users interact with AI. The shift toward agentic AI—where agents work autonomously rather than responding to brief prompts—dramatically increases inference demand per user. This is driving the unprecedented infrastructure buildout in data centers, GPUs, and edge computing.