Inference Optimization
Inference Optimization is the integrated discipline of making AI models run faster, cheaper, and more efficiently when serving real-world requests. While much of AI's attention has focused on training — how to make models smarter — the practical bottleneck in 2026 is serving: how to make smart models respond to billions of queries per day without bankrupting the operator or melting the datacenter. Inference optimization combines techniques from quantization, distillation, caching, hardware design, and systems engineering into a coherent practice that is now as important as training methodology.
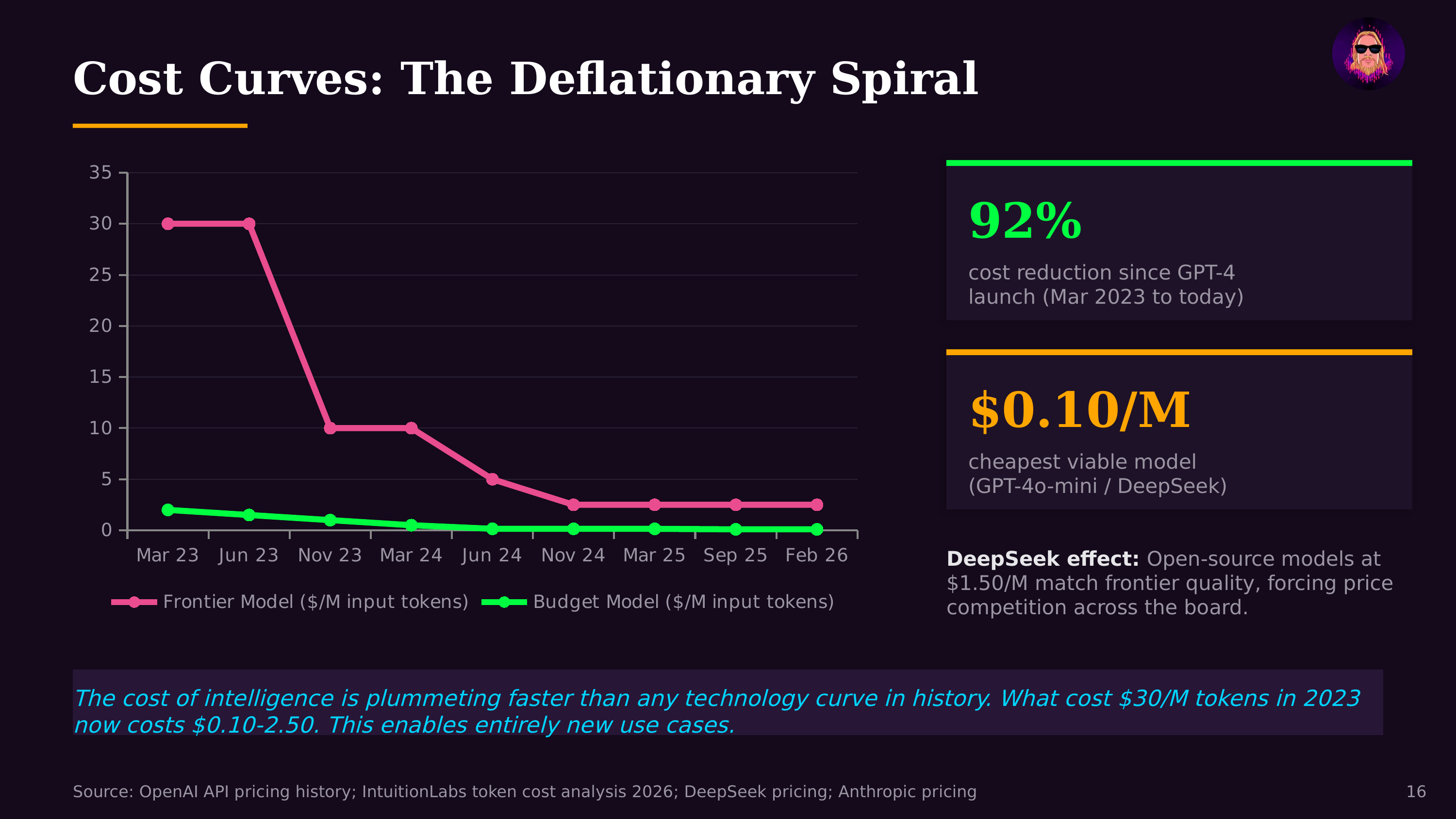
The economics drive everything. As of 2026, inference compute demand is estimated to exceed training compute demand for the major AI providers. Every ChatGPT conversation, every Copilot code suggestion, every AI-powered search result requires inference. At scale, even small efficiency gains translate to millions of dollars in savings and meaningfully lower latency for users. The difference between a 50ms and 500ms response time determines whether an AI feature feels instant or frustrating — and whether an agentic system can complete a multi-step task in seconds or minutes.
Key techniques that define the field:
Speculative decoding uses a small, fast "draft" model to generate candidate tokens, which the larger model then verifies in parallel. Since verification is faster than generation, this can achieve 2-3x speedups without any quality loss. KV-cache optimization reduces memory usage by efficiently storing and reusing the key-value pairs computed during attention, enabling longer context windows and larger batch sizes. Continuous batching dynamically groups incoming requests to maximize GPU utilization rather than processing them one at a time. Quantization pipelines (int8, int4, and emerging formats) reduce model precision from 16-bit to lower-bit representations, cutting memory and compute by 2-4x with minimal quality degradation. Pruning removes unnecessary model parameters. In practice, these techniques are used in combination — a model might be quantized to int4, served with speculative decoding, using continuous batching with optimized KV-cache management.
Hardware specialization is accelerating. While NVIDIA GPUs dominate training, inference has attracted specialized hardware: Groq's Language Processing Units (LPUs), which use deterministic compute for predictable latency; Cerebras wafer-scale chips optimized for throughput; Amazon's Inferentia/Trainium chips purpose-built for AWS inference workloads; and Apple's Neural Engine for on-device SLM inference. The diversity of inference hardware reflects the diversity of inference workloads — batch processing, real-time chat, edge deployment, and agentic multi-step reasoning all have different optimization profiles.
The rise of test-time compute makes inference optimization even more critical. When models are encouraged to "think longer" on hard problems, inference costs per query can increase by 10-100x. Without aggressive optimization, the economics of reasoning models would be prohibitive. The tension between "let the model think more" and "keep serving costs manageable" is one of the defining engineering challenges of 2026 AI deployment.
Further Reading
- Model Quantization Inference Optimization — Core technique for inference efficiency
- Test-Time Compute — Why inference optimization matters more than ever
- AI Inference — The broader inference landscape