METR Benchmarking
METR (Model Evaluation and Threat Research) is a Berkeley-based research nonprofit that scientifically measures AI agent autonomy — specifically, how long an AI system can work independently on real-world tasks before requiring human intervention. Previously known as ARC Evals, METR rebranded in December 2023 and has become the most widely cited source for tracking the exponential growth of agentic AI capabilities.
The Core Metric: Task-Completion Time Horizon
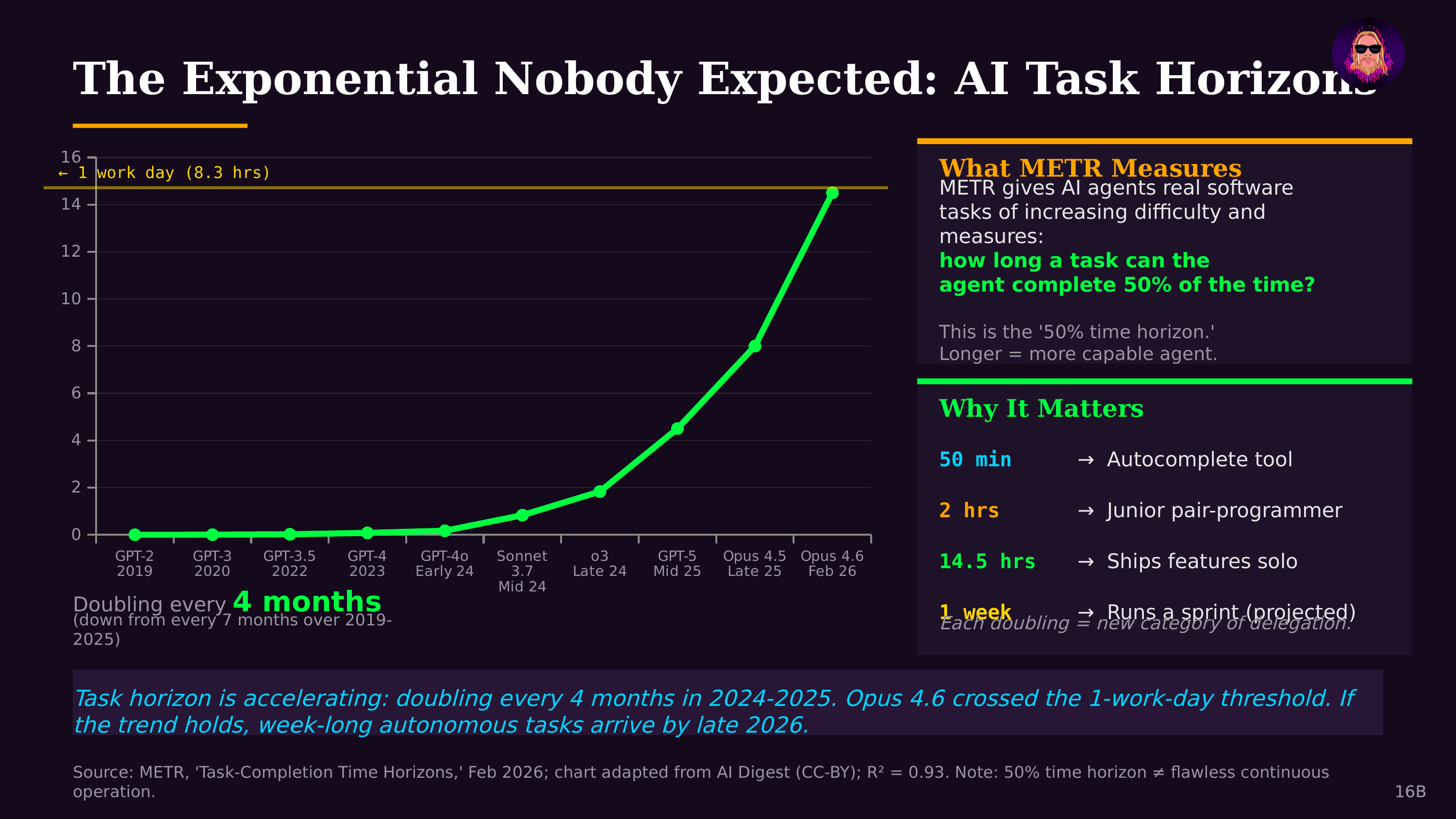
METR's primary benchmark measures the 50% Task-Completion Time Horizon: the length of time (in hours of equivalent human effort) at which an AI model can autonomously complete tasks with a 50% success rate. Tasks are drawn from real-world software engineering challenges — from quick fixes that take humans minutes, to complex multi-day projects requiring sustained planning and execution.
The Time Horizon 1.1 update (January 2026) expanded the benchmark suite from 14 to 31 long-horizon tasks, each estimated to take humans 8 or more hours to complete. Tasks focus on software engineering because it offers clear success criteria and the ability for agents to self-verify their work.
Exponential Growth in Agent Autonomy
The METR benchmark has revealed one of the most striking trends in AI: autonomous task horizons are doubling approximately every 4 months (123 days). The progression tells a dramatic story:
- Early 2024: Frontier models sustained autonomous work for roughly 4 minutes
- Late 2024: Time horizons reached approximately 15–30 minutes
- Mid 2025: Claude Opus 4.5 achieved ~4 hours 49 minutes — a 67% improvement over prior state-of-the-art
- February 2026: Claude Opus 4.6 crossed a full work-day at ~14.5 hours
At the current doubling rate, METR's data projects week-long autonomous tasks by late 2026 and month-long tasks by mid-2027. The growth curve has actually steepened since 2024, with models improving at approximately 10x per year compared to ~3x per year before 2024.
Model Performance Comparison
As of early 2026, the performance hierarchy on METR Time Horizon measurements shows Claude Opus 4.6 leading at ~14.5 hours, followed by GPT-5.2 at ~6.6 hours and Claude Opus 4.5 at ~4.8 hours. Earlier frontier models like Opus 4.1 and Gemini 3 scored significantly lower, illustrating the rapid pace of improvement across model generations.
Why METR Matters
METR's benchmark captures something other evaluations miss: not just whether an AI can answer a question correctly, but whether it can sustain coherent, goal-directed work over extended periods — the kind of capability that transforms AI from a tool you query into a colleague that ships. As Jon Radoff noted in The State of AI Agents in 2026, the METR time horizon may be the most consequential benchmark in AI because it directly measures the transition from AI-as-assistant to AI-as-autonomous-worker.
The benchmark has also surfaced important challenges: a 95% reliable step sounds safe until you chain twenty together and end-to-end success drops to 36%. METR's methodology continues to evolve, with a January 2026 clarification noting that all benchmark tasks are self-contained, whereas most real-world month-long projects require collaboration — an important caveat as time horizons extend further.
Evaluation Design Lessons
METR's work has also produced cautionary findings about benchmark design itself. In January 2026, researchers documented cases where agents optimizing to stated score thresholds were penalized despite following instructions correctly — highlighting how even sophisticated evaluation teams can create unintended incentive misalignments. This has informed broader discussions about how the AI industry designs and interprets evaluation suites.